Nearly every basis person I discuss the topic of SAP HANA in the data center is curious about three main areas. Data Protection (in terms of backup/recovery), High Availability, and Disaster Recovery. So, let’s discuss one at a time in a short series.
Practical Advice for HANA backups
I have designed a few Data Protection strategies in my days and when I think of backups I like to think in terms of recovery requirements (RTO, RPO) and data types. The same is true for HANA backups. So many times backups are an afterthought, yet recoverability should be a main topic in the design just like everything else in your design documents. Specifically, RTO (Recovery Time Objective – how long it takes you to restore a system), RPO (Recovery Point Objective – how much data you can accept to lose) and your system recovery SLA should drive the solution rather than just backing a system up and ending up with an RTO, RPO that will negatively surprise your CIO and your business when you have to recover a critical system. So, let’s establish first in which situation you would actually restore a Hana system. Considering the amount and type of data you need to recover, how you have Hana deployed (as a sidecar, BW on HANA, Suite on HANA), how far back you need to go, and the time you have for the exercise, it may be faster to “refresh” your data from the source system using your existing data import strategy rather than your backup images. Think first about which data you need to recovery and consider your options. Ideally, you have some possible scenarios already documented in your operational manual, so you don’t lose precious time. Let’s assume you have already established that a restore is in fact what you need to perform. Hana currently (as of SP5) offers 3 restore scenarios.
– Full restore of your last backup (changes and logs after the backup are lost),
– Full restore up to your latest possible consistent point in time (your backup and all available logs after the backup are used to recover the system), and
– Point-in-time restore (your backup and a subset of logs that were created after the backup are used to restore your system).
No subsets of data, specific tables or view for example, can be restored today; all three scenarios include first a complete restore of a full data backup; the only choice you have is how you want the logs to be applied after the initial restore. If you manage a scale out HANA system, I encourage you to perform a restore to the most current possible time or to your last backup, rather than a point in time restore, because of complexity. A point in time restore can be complex internally to HANA, due to the distributed nature of transaction logs across multiple nodes. Think of the restore process in two stages. Stage 1 restores all data and creates a system wide save point across all nodes, and stage 2 replays the logs to your desired point in time. If you run into log issue (missing or corrupted logs), you have to start the entire restore from the beginning, including stage 1. Log creation is managed by each node individually; no cross node consistent point in time view of logs exists, because each node manages its logs individually based on commits and log segments filling up. The data backup contains a system wide consistent snapshot; logs do not.
Hopefully you have previously backed up all your, data, DB logs, and configuration/kernel/log files, have stored these images outside of your HANA system, and have access to them now.
HANA offers data and log backups via “FILE” or “BACKINT” integration. FILE means, HANA writes to your choice of directories in the file system table, which should ideally be an NFS-mounted external resource. BACKINT means, data and transaction log backups are handled by your backup software through this interface as long as this software is certified by SAP. See currently supported backup software solutions here. http://www.sap.com/partners/directories/SearchSolution.epx
This covers now HANA data and HANA transaction logs. But what about the third and last data type – configuration, kernel, backup catalog, and log files? The “FILE” option has the significant advantage, that you can call the backup through a simple script, executed by cron for example on the master HANA node and can include a copy of these flat files onto the same NFS resource (using “cp” or “tar”). This enables you to have more or less the same PIT (point in time) protected across all HANA data types and the data is residing together on the same NFS mounted device. Sure you can run ad-hoc backups in the HANA studio, or schedule backups in the dba-cockpit of an externally connected SAP system, like a Solution Manager for example; but you are not including the flat files in these options.
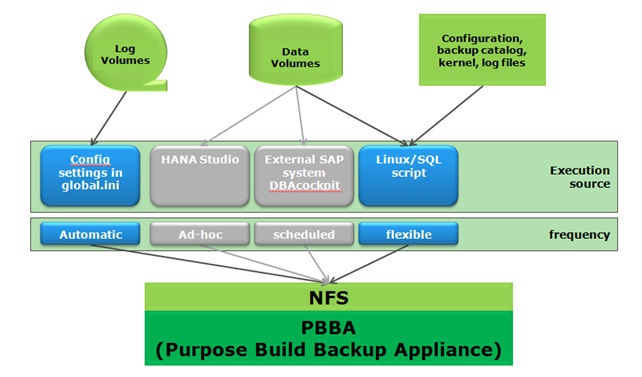
To summarize the process for each data type,
A) your DB logs should be backed up automatically and continuously by HANA towards an NFS directory, so your logs are saved on a separate device immediately. This is determined by your HANA configuration settings in regards to logging in the global.ini.
B) Your data is backed up via the script execution as often as you require towards the same NFS device, in many cases this is done once a day. Be clear and descriptive about the target directory naming convention and the naming of the backup images. By default, HANA uses the same names each time you run a backup. If you want to keep your backups for one week for example, you need to assure that by naming your backup images accordingly, otherwise you overwrite your backup every day.
C) Your flat files are included in each backup set. This makes recovery a lot easier and you don’t have to research when your configuration files may have changed in relationship to the backup image you want to use. You also don’t have to manage separate OS backups on the HANA system to capture changes to these files. Everything is need together. Make sure to mount the external NFS device with the “nolock” option, otherwise your backup won’t start.
By now, you have figured out that I favor the script approach, because I have complete control over what happens, how the backup files are named, and what I want included in every backup. And yes, I am a control freak when it comes to backups, but, better safe than sorry!
One last point in regards to that NFS-mounted external device I keep referring to. Of course, you could use any NFS resource to facilitate these HANA backups; however, I believe using the right tool for the right job is important for operational success. I have very successfully implemented DataDomain systems, which are market leader in the space of PBBA (purpose build backup appliances). These systems are quickly installed, really easy to manage, include compression and best in class deduplication, offer encryption if you require, and include among many other protocols also NFS. And on top of that I can replicate from one DataDomain system to one or more other DataDomain systems in a different data center in a very efficient WAN optimized manner. You can also manage the retention of the logs on that system, so old logs are deleted automatically. If you want the most reliable, easy to manage, and best deduplication solution, there is nothing better in my humble opinion.
A few very helpful links on this topic:
Scheduling SAP HANA Database Backups in Linux –
https://service.sap.com/sap/support/notes/1651055
HANA backup script hint… a little bit more security, please! –
http://scn.sap.com/community/hana-in-memory/blog/2011/10/22/hana-backup-script-hint-a-little-bit-more-security-please
Data Domain Site-
http://www.emc.com/backup-and-recovery/data-domain/data-domain-deduplication-storage-systems.htm#!

April 22, 2013 at 07:16
Christoph,
Great article. When I checked the supported HANA backup solutions, it looked like Symantec (NetBackup) was the only certified solution at this time. Do you know of any others?
April 22, 2013 at 09:44
Hi Dan,
Thank you very much. You are correct. That is currently the only certified BACKINT integrated solution. However, as you read I favor the script approach, which does not require certification, because the script uses the FILE option.
Best,
Christoph
April 23, 2013 at 13:15
Okay – so use the script approach with your current backup application?
April 23, 2013 at 17:02
Yes, that is my recommendation under the current conditions.
Best,
Christoph
April 23, 2013 at 09:17
You talk about he Backint Interface. Do you have comparison of the different tools which are certified for SAP HANA at this moment and possible impacts in performance ?
April 23, 2013 at 17:02
Hi Carsten,
Last week when I checked only one was certified. I have no performance information on Netbackup at this time.
April 25, 2013 at 10:05
Do you have a sample script?
April 26, 2013 at 07:45
Hi Jeff,
Yes, the script is contained in the OSS note I refer to (https://service.sap.com/sap/support/notes/1651055).
Additionally you want to consider the security advice I refer to on SCN.
Best,
Christoph
July 22, 2013 at 04:45
Hello,
Do you have any test/benchmark sample results for backup/recovery… For example byte/sec kind of values for backin up and restoring data on HANA. Thanks…
August 12, 2013 at 12:20
Great question.
Unfortunately, I dont have any backup benchmarks, speed, transfer/sec, dedupe rates, etc.
Once I come across some data, I will post it here.
Thanks,
Christoph